Multilinear Mixture of Experts:
Scalable Expert Specialization through Factorization
James Oldfield1,
Markos Georgopoulos,
Grigorios G. Chrysos2,
Christos Tzelepis3,
Yannis Panagakis4,5,
Mihalis A Nicolaou6,
Jiankang Deng7,
Ioannis Patras1
1Queen Mary University of London
2University of Wisconsin-Madison
3City University of London4National and Kapodistrian University of Athens 5Archimedes/Athena RC 6The Cyprus Institute 7Imperial College London
ArXiv 2024
Abstract
The Mixture of Experts (MoE) paradigm provides a powerful way to decompose inscrutable dense layers into smaller, modular computations often more amenable to human interpretation, debugging, and editability. A major problem however lies in the computational cost of scaling the number of experts to achieve sufficiently fine-grained specialization. In this paper, we propose the Multilinear Mixutre of Experts (MMoE) layer to address this, focusing on vision models. MMoE layers perform an implicit computation on prohibitively large weight tensors entirely in factorized form. Consequently, MMoEs both (1) avoid the issues incurred through the discrete expert routing in the popular 'sparse' MoE models, yet (2) do not incur the restrictively high inference-time costs of 'soft' MoE alternatives. We present both qualitative and quantitative evidence (through visualization and counterfactual interventions respectively) that scaling MMoE layers when fine-tuning foundation models for vision tasks leads to more specialized experts at the class-level whilst remaining competitive with the performance of parameter-matched linear layer counterparts. Finally, we show that learned expert specialism further facilitates manual correction of demographic bias in CelebA attribute classification.
Method Overview
MMoE layers fuse large numbers of (potentially hierarchical) experts' operations on an input vector in an efficient manner. By design, MMoE layers scale gracefully to tens of thousands of experts by performing implicit computation in factorized form:
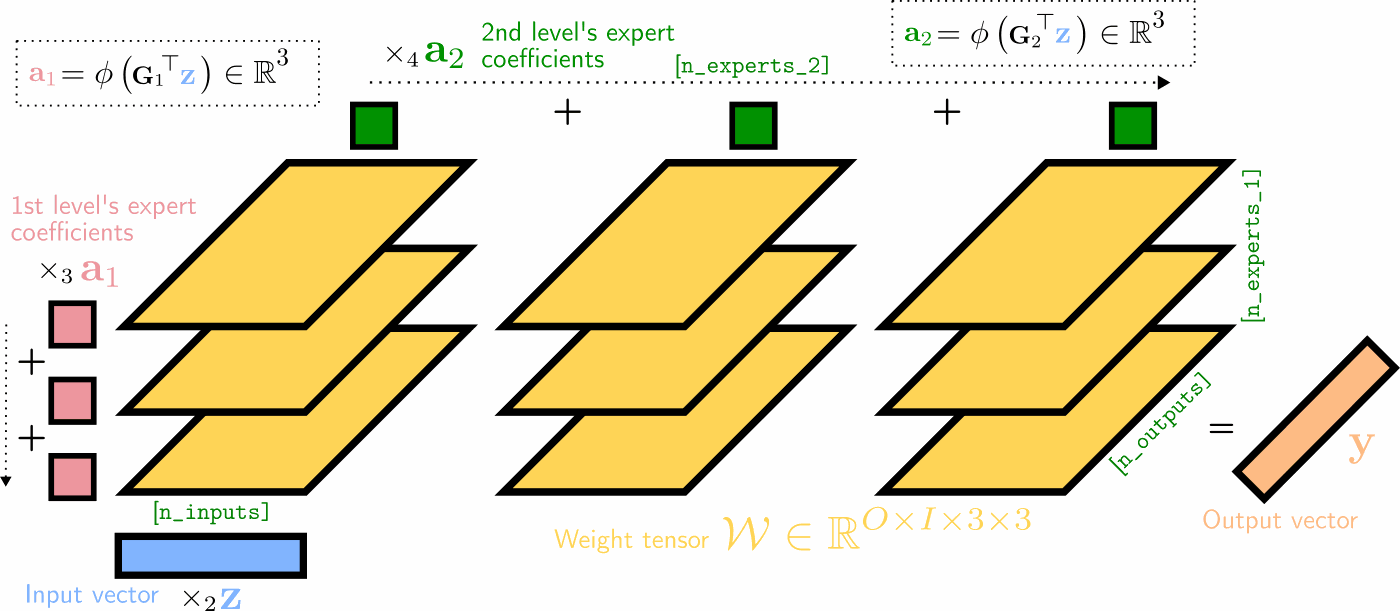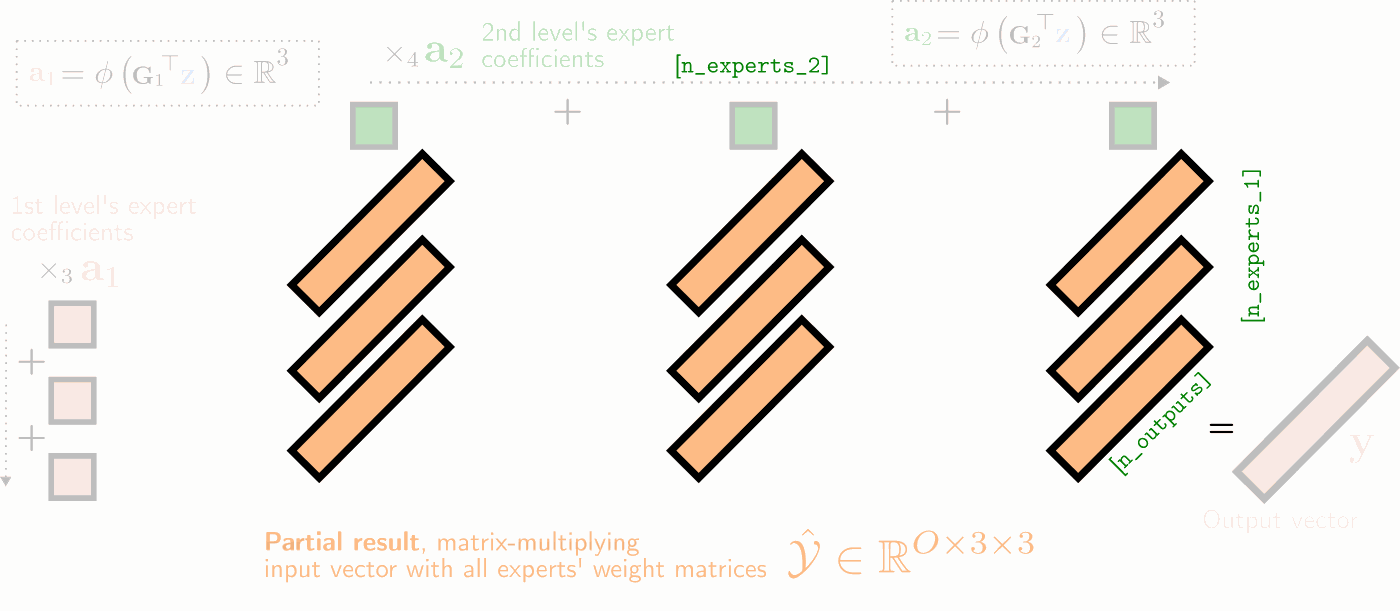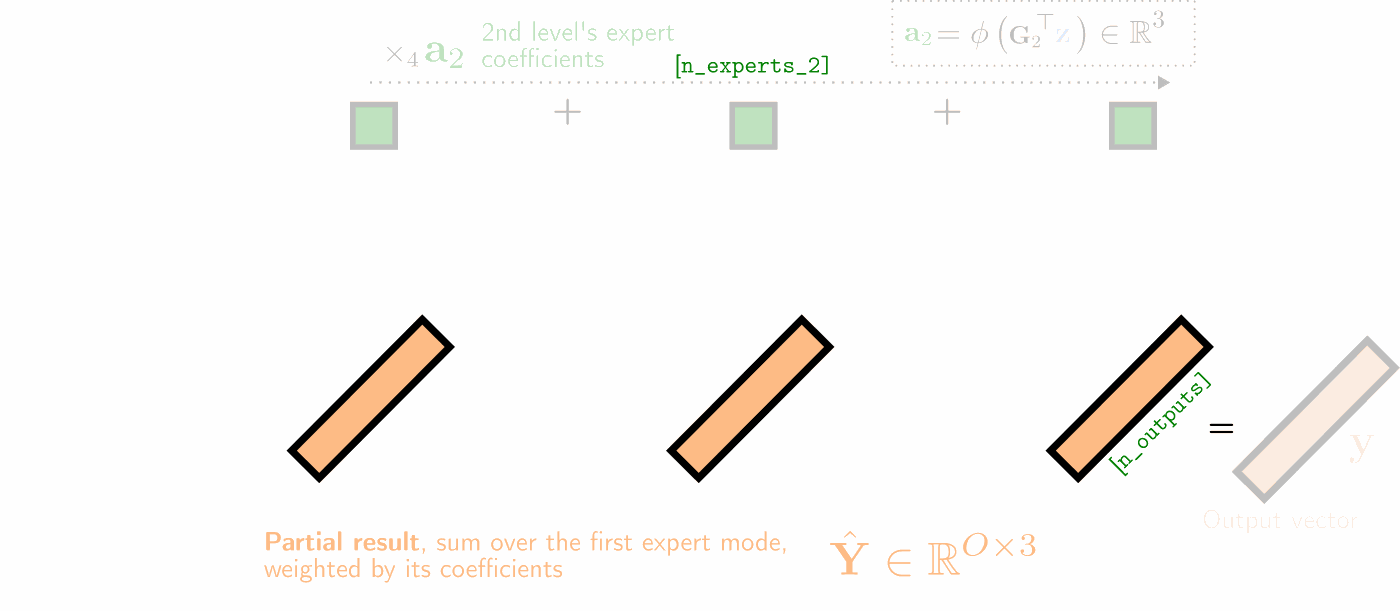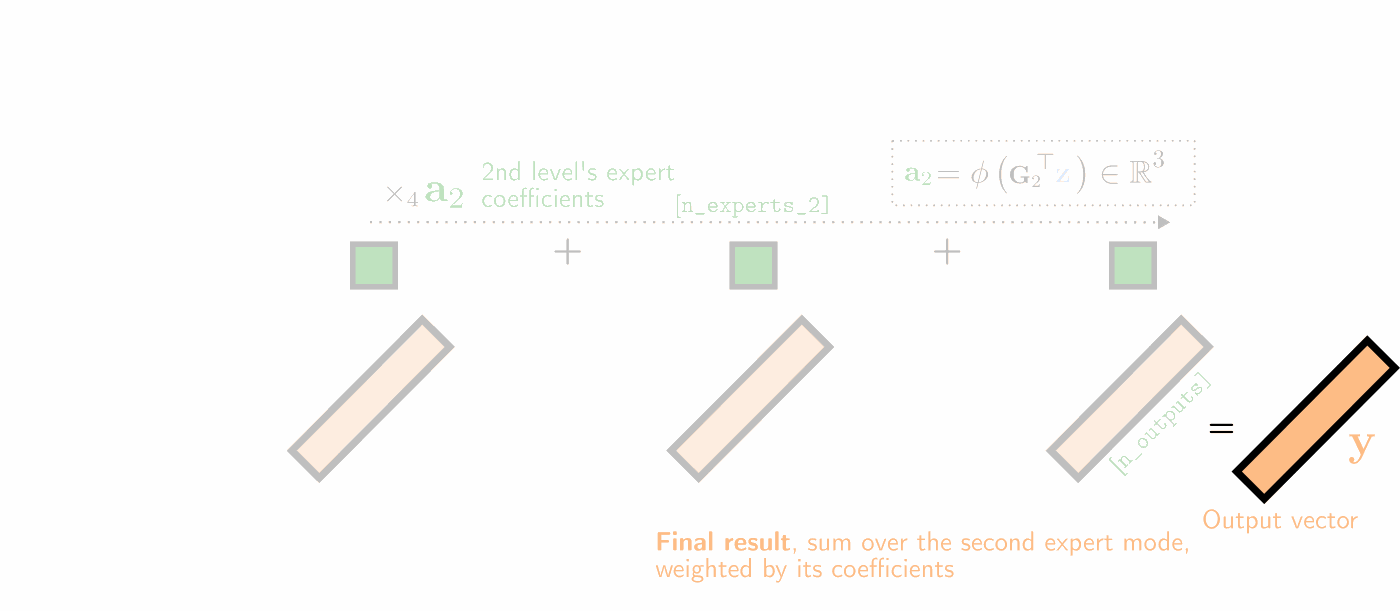
Illustration of a two-hierarchy MMoE layer's (unfactorized) forward pass as a series of tensor contractions, with 3 experts at both levels of hierarchy. The experts' weight matrices are visualized as 2D horizontal slices in yellow, which are (1) matrix-multiplied with the input vector \(\mathbf{z}\), (2) summed over the first expert mode (weighted by the first expert coefficients \(\mathbf{a}_1\) in red), and (3) summed over the second expert mode (weighted by the second expert mode's coefficients \(\mathbf{a}_2\) in dark green).
The MMoE layer forward pass
The unfactorized MMoE forward pass visualized above with \(E\) levels of hierarchy more generally is parametrized by the experts' collective weight tensor \(\mathcal{W}\in\mathbb{R}^{O\times I\times N_1\times\ldots\times N_E}\) and expert gating matrices \(\mathbf{G}_e\in\mathbb{R}^{I\times N_e}\) which yield the expert coefficients \(\mathbf{a}_e=\phi(\mathbf{G}_e^\top\mathbf{z})\) at each level \(e\) of hierarchy. Its forward pass for input vector \(\mathbf{z}\in\mathbb{R}^I\) can be re-written explicitly as a convex combination of all \(\prod_{e} N_e\) experts' output:
$$\mathbf{y} = \sum_{n_1=1}^{N_1}{a_{1}}_{n_1}\ldots\sum_{n_E=1}^{N_E}{a_E}_{N_E} \big(\underbrace{\mathbf{W}_{::n_1\ldots n_E}}_{O\times I}\mathbf{z}\big). \nonumber$$In the paper, we derive 4 factorized MMoE variants and their corresponding fast forward passes--each of which provides a different trade-off regarding parameter count and RAM requirements. Operating in factorized form, all MMoE models need never materialize the full weight tensors. This greatly reduces the computational demands of scaling the number of experts.
Results
Expert specialization
When fine-tuning foundation models (such as CLIP) for vision tasks, we find that increasing the number of experts in MMoE layers leads to more specialized experts at the class-level.
We quantify this by asking a counterfactual question about each expert in turn--intervening in the model's forward pass (setting each expert's weights to 0) and recording the counterfactual change to the test set's class predictions.
Using the pre- and post-intervention class accuracies, we compute a measure of mean "expert polysemanticity" (i.e. the extent to which an expert's computation is responsible for the accuracy for one class and nothing more) across all experts that have any non-zero effect on class predictions:
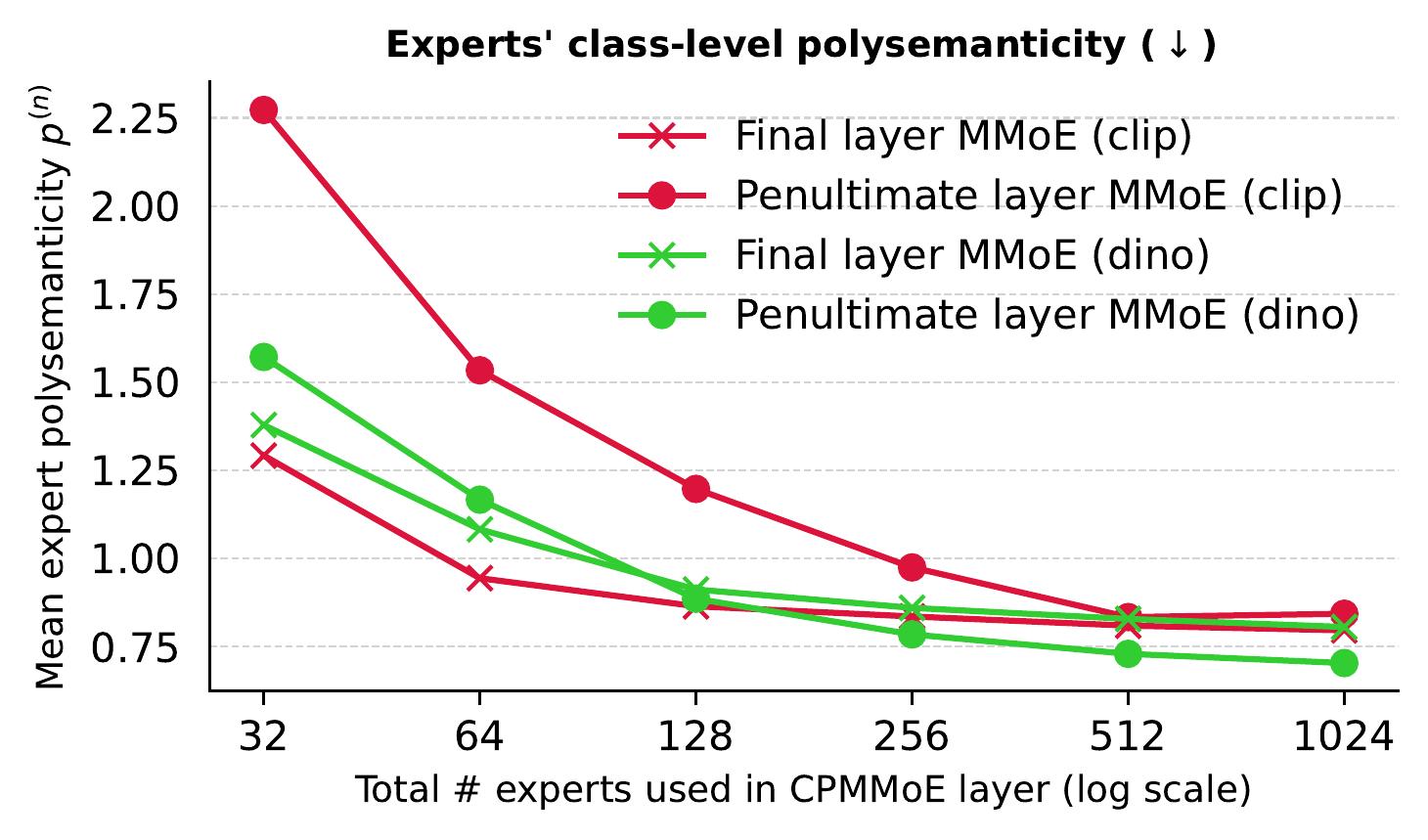
Increasing the total number of MMoE experts leads to individual experts increasingly responsible for a single subtask: classifying all inputs of just one class.
The counterfactual change to class predictions when intervening can also be visualized on a per-expert basis, plotting the normalized per-class accuracy drop, e.g. for CPMMoE models with 32 vs 1024 total experts:
Qualitative results
256 vs 32 total experts for a CPMMoE model. The larger the total number of experts, the more the experts appear to specialize to particular visual themes. Shown in each cell below are random images from the training set of those with corresponding expert coefficient of at least 0.5, for the first few experts numerically:

Expert re-writing
MMoE expert specialism facilitates more targeted model editing. As an example, we perform manual correction of demographic bias in CelebA attribute classification. Fine-tuning CLIP with MMoE final layers, we can modify the output logits for the combination of experts processing demographic subpopulations (e.g. to mitigate bias towards the "old females" subpopulation for "age" prediction):

BibTeX
If you find our work useful, please consider citing our paper:
@misc{oldfield2024mmoe,
title={Multilinear Mixture of Experts: Scalable Expert Specialization through Factorization},
author={James Oldfield and Markos Georgopoulos and Grigorios G. Chrysos and Christos Tzelepis and Yannis Panagakis and Mihalis A. Nicolaou and Jiankang Deng and Ioannis Patras},
year={2024},
eprint={2402.12550},
archivePrefix={arXiv},
primaryClass={cs.CV}
}